Straight through Ethernet cabling (cable entering from bottom, pins up, clip down)
Cross over cable (cable entering from bottom, pins up, clip down)

Straight through Ethernet cabling (cable entering from bottom, pins up, clip down)
Cross over cable (cable entering from bottom, pins up, clip down)
Updated 2025/03/12 – Additional migration configuration
In my previous post How to Build a ProxMox Hypervisor Cluster with NAS Disk I described the configuration of QNAP NAS iSCSI LUNs to support ProxMox hypervisor servers with the goal of highly available high performance disk. In this post I will outline the configuration of VMs within the ProxMox cluster to gain disk replication across specific hypervisor hosts. Replication is a pretty slick and painless way to provide (higher) availability of VMs both for maintenance activities as well as host node failures without the complexity of full HA Cluster configuration. I do have pretty substantial experience with Linux Virtual Sever (LVS) and commercial clustering solutions, so I will likely address the ProxMox version of that capability in a future article.
To recap from my previous article, each of the three (3) ProxMox hosts has a pair of mirrored HDD, which are only used for ProxMox OS. Each host also has a single SSD for the occasional IOPs hungry VM. Although single local disk does present a failure risk, at this point in my network design, that is a deliberate choice. Any VM that cannot tolerate that single point of failure is required to use the iSCSI zpool. Also the goal at this point is not to go overboard on elimination of every single point of failure, just the highest probabilities. At this point there are three (3) different hosts, three (3) separate UPS, all using multiple network adapters for performance management. QNAP NAS iSCSI volumes are used for disk redundancy.
Adding replication to any of my ProxMox VMs is made straight forward by a couple of design choices. Every ProxMox host has the same ZFS zpool storage groups which are all named the same across each host – currently two: zfs-ssd1 (local SSD on each host) and zfs-iscsi1 (QNAP NAS served iSCSI LUNs dedicated to each host). Technically VMs could use the local ZFS rpool, however I’ve chosen to keep VM disks completely separate from local ProxMox OS storage.
Generally the entire process involves three simple steps: Create VM, Configure Replication, Request Migration.
We can create the guest VMs as usual, but must specify virtual disk volumes within the zfs-ssd1, zfs-iscsi1, or both ZFS storage pools.
Use host > zfs-ssd1 > Summary and host > zfs-iscsi1 > Summary pages in the UI to determine capacity left on each host. As you would expect, allocation of space for a VM needs to take place on all hosts on which that VM is desired to be replicated. Replicating a VM to all hosts will take 3x the storage allocation versus having no replication.
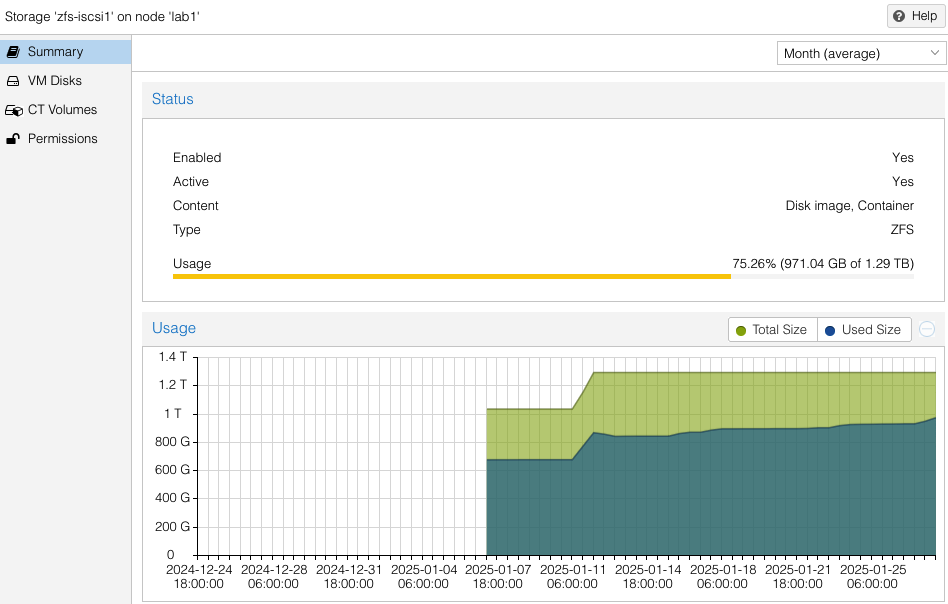
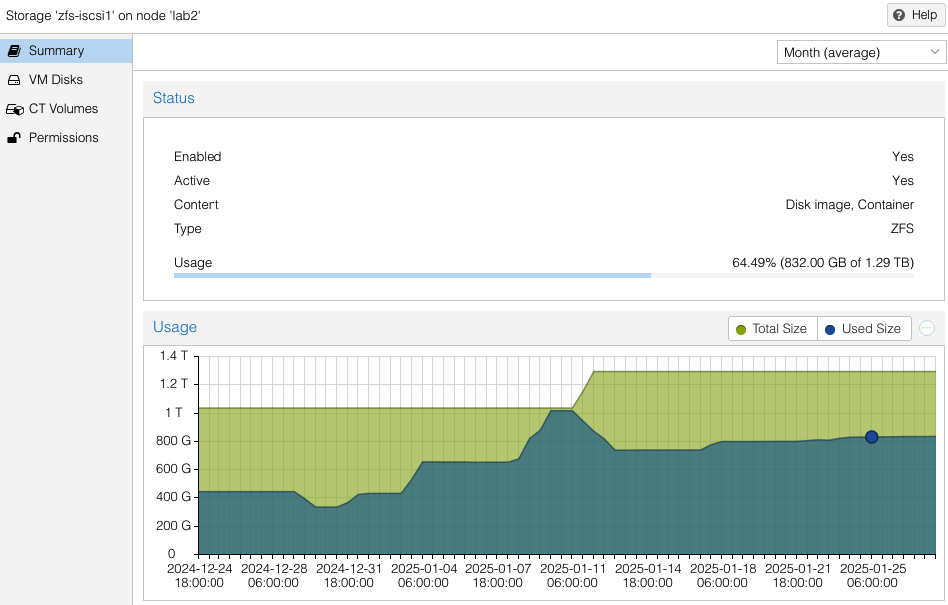
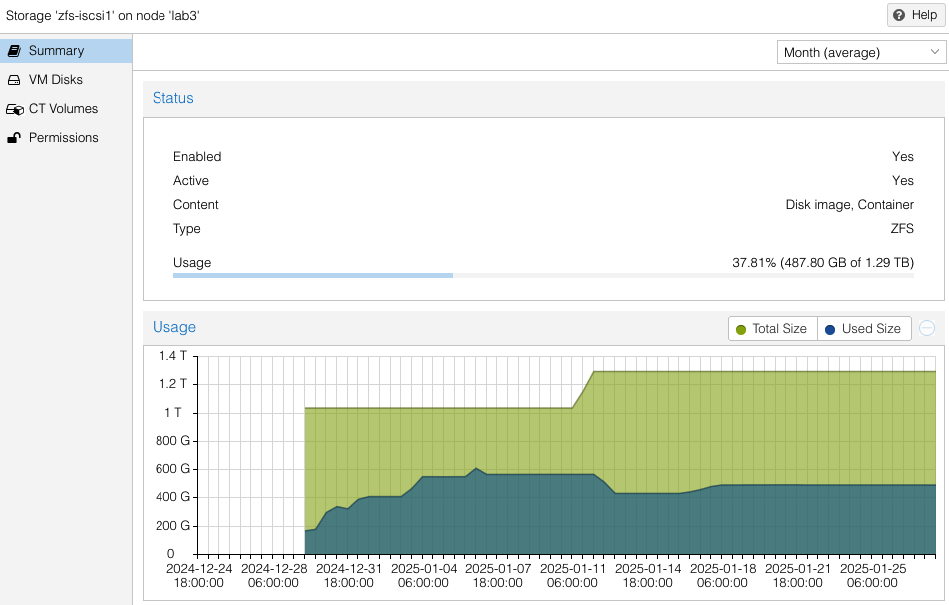
Note the availability and allocation of iSCSI storage on each of the three (3) ProxMox hosts. Might seem like lab2 was setup first, then lab3, then lab1. Actually both lab3 and lab1 were rebuilt after the initial three (3) node cluster was built. No loss of VMs occurred since I had all VMs replicated to the surviving cluster nodes while I did a rolling rebuild – there was always at least two cluster hosts. Also you can see at the beginning of January (01-11) zfs-iscsi1 pool was running out of space to allocate to either VMs or replication. I simply added another 250GB iSCSI LUN from the QNAP and extended the zfs-iscsi1 pool. More on that later.
VM Example – Replication to One Host
Our first VM will have multiple virtual disks located in the zfs-iscsi1 pool. These are all in the zfs-iscsi1 pool, however it could just as easy have a mix of zfs-iscsi1 and zfs-ssd1 virtual disks – presuming there is sufficient space available in the target host pools to which we intend to replicate. There is no restriction of number of pools used by the VM, just as long as those pool names are available on the target host.
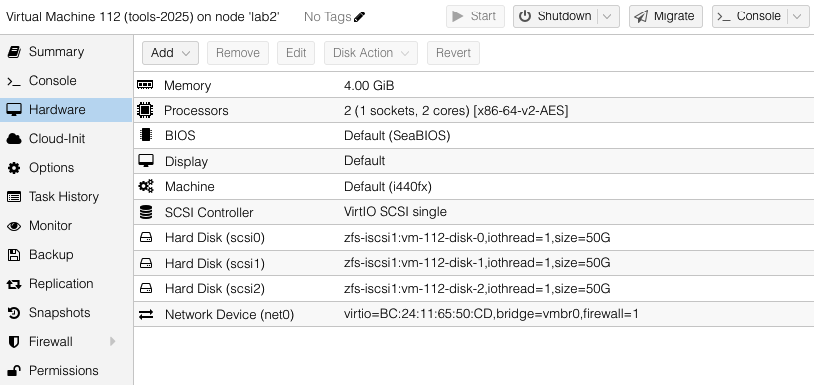
We will configure the tools-2025 VM to replicate to one other host – lab1.
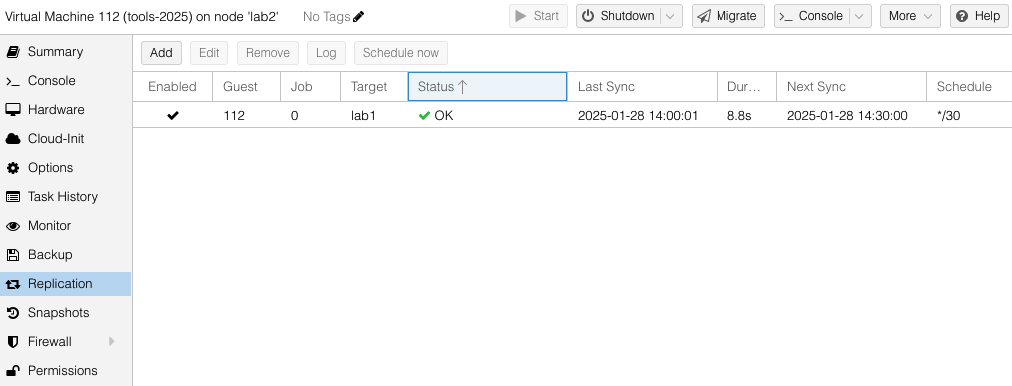
While creating the replication job, dialog boxes are used to select destination host(s) and the frequency of the replication. Sync jobs are run by taking zpool snapshots and sending those snapshots to the target host. Typical cadence would be every 15 minutes for sync of important VMs. Offline or less important VMs can sync hourly, nightly or even monthly – similar options as what you would find with Linux crontab jobs. Shortly after you have created the replication job, ProxMox will get it running in the background.
Difference Between Replicate and Migrate
Replication jobs run on a regular basis to push ZFS snapshots to the target hosts. When a migration of VM from one host to another is requested – literally a button push – the replication will speed the migration through the use of snapshots that are already on the target host. It is not necessary to have replication jobs enabled in order to migrate a VM, however it will take longer to migrate the more disk data that has to be synchronized. When migrating VMs with a large amount of storage that has not been replicated, it can take a very long time to run and possibly not successfully complete in the case of attempting live migrations. More on this in the next example.
On each host, one can see the VM virtual disks that have been replicated by looking at host > ZFS pool name > VM Disks. This list will be the same on both the source and the target hosts.
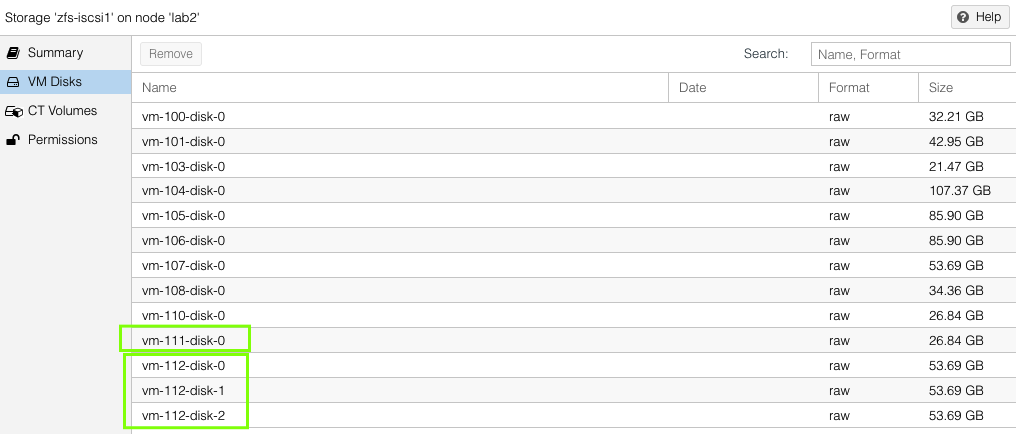
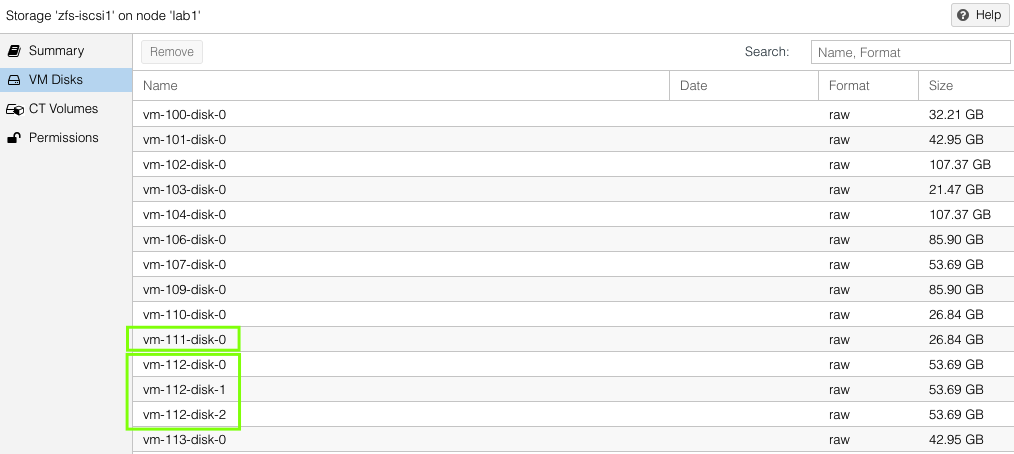
VM Example – Replication to Two Hosts
Our second VM will have a single virtual disks located in the zfs-iscsi1 pool but is going to replicate to both of the other standby ProxMox hosts.
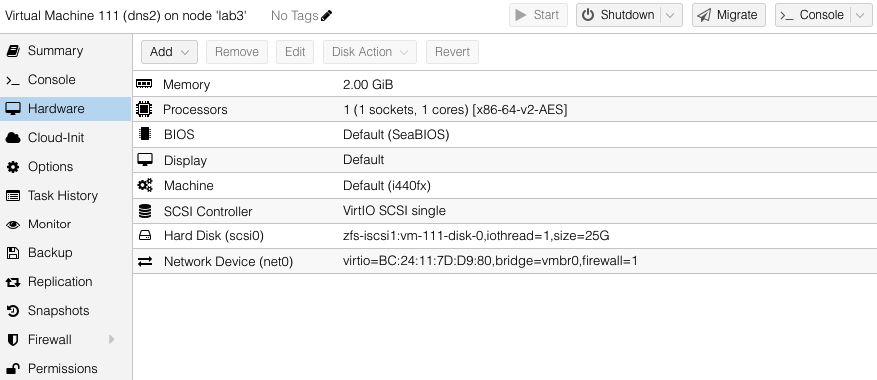
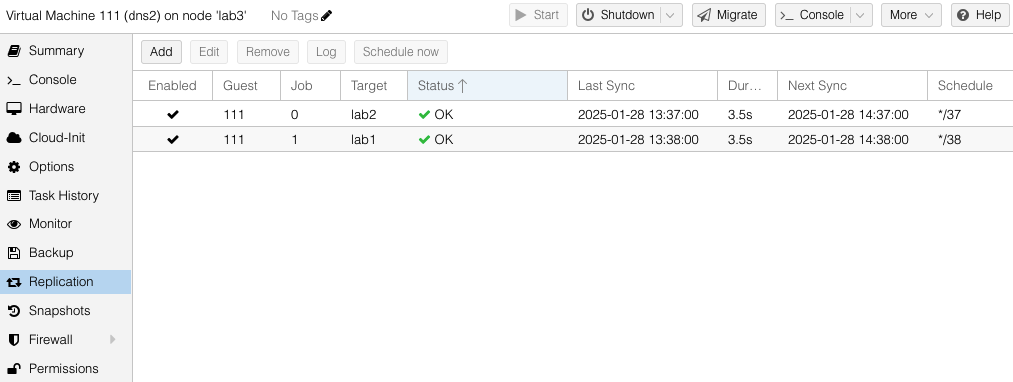
You can see both the replication jobs configured for VM 111, one to lab1 and the other to lab2. The replication job frequency is completely flexible however I have chosen to offset the schedules to reduce the disk use bandwidth.
Migrations can be either offline (VM powered off) or live. To request a migration, we just select the Migrate button under the VM to be moved. Live migrations are just that – it replicates then moves a running VM to a target host with no perceived downtime.
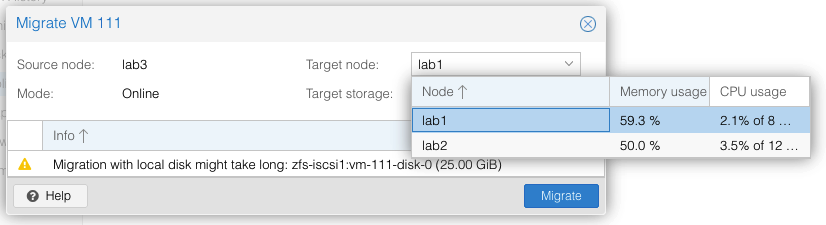
The migrate menu will show you the current CPU and memory load of the available target systems. Fastest migrations are offline VMs that have had a recent replication job complete. Large VMs with lots of disk and memory and no prior replication have been known to fail to migrate – it is complicated to snapshot live memory for synchronization to a target host. All but the largest of VMs I have (looking at you elasticsearch) have no problems in migrating live in less than maybe 30 seconds for 4GB of memory.
In the case there is sufficient CPU and memory capacity on the target host, one can request a Bulk Migration operation from the main menu of the source host. I have used this several times to perform maintenance on cluster hosts where downtime is needed. The live migration of VMs is amazing .. makes life so much easier, with no VM reboot or downtime.
The scenarios I have outlined so far are most common, however one of the key use cases I wanted to be able to cover is what happens when a ProxMox host unexpected fails.
Fortunately a surviving host can start the failed VMs from last transferred snapshot. Clearly any data that was changed after the last replication snapshot will be lost. Not great for any VMs that are hosting applications / functions that are frequently changing, such as database servers. This ability is still sufficient for my use case and situation – low chance of host failure causing total data corruption (still not zero but far better than what I had before). A future article will focus on use of HA Cluster features including global cluster filesystems to cover those systems I have that have high(er) integrity requirements.
For example purposes, assume a three (3) node ProxMox hypervisor cluster without HA as I’ve described above. Two ZFS disk pools, zfs-ssd1 and zfs-iscsi1. We’ll reference six (6) guest VMs that have been created and configured to be using disk volumes within the zfs-iscsi1 pool. Currently two (2) VM are on each ProxMox host. Replication jobs have been configured on all VM to replicate every 15 minutes to both other ProxMox hosts. VMs on lab1 are vm-1 and vm-2. VMs on lab2 are vm-3 and vm-4. VMs on lab3 are vm-111 and vm-112. In this case assume lab3 has suddenly failed and is completely offline/powered off. The following process will allow a restart of vm-111 and vm-112 on either lab1 or lab2. For simplicity let’s restart vm-111 on lab1 and vm-112 on lab2.
Verify Replication
We need to confirm that the replication data for vm-111 and vm-112 exists on lab1 and lab2:
lab1:
zfs list | grep "vm-111"
zfs-iscsi1/vm-111-disk-0 28.2G 323G 2.81G -lab2:
zfs list | egrep vm-112
zfs-iscsi1/vm-112-disk-0 83.9G 348G 33.1G -
zfs-iscsi1/vm-112-disk-1 71.5G 348G 20.7G -
zfs-iscsi1/vm-112-disk-2 55.2G 348G 4.42G -Since we see datasets zfs-iscsi1/vm-111-disk-0 and zfs-iscsi1/vm-112-disk-0, the replication data appears to be intact.
Import the VM Configuration
Each VM has a configuration file in /etc/pve/qemu-server/ on the Proxmox cluster.
Check if the config files for vm-111 are on lab1 and vm-112 are present on lab2:
lab1# ls /etc/pve/qemu-server
100.conf 101.conf 102.conf 103.conf 111.conf 113.conf lab2# ls /etc/pve/qemu-server
100.conf 112.conf 118.confSince the config files exist, we can proceed to the next step. If those files do not exist, move the configuration files manually from the lab3 replicated configuration. ProxMox uses cluster filesystem for /etc/pve directory so those files should be in the /etc/pve/qemu-server/lab3 directory.
lab1# cd /etc/pve
lab1# mv nodes/lab3/qemu-server/111.conf qemu-server/Next we need to verify manual adjustment of VM configuration not needed. Ensure the disk paths in the configuration files match the replicated ZFS datasets on the new host. Since our design uses the same ZFS zpool names on all ProxMox hosts, should not need to change the paths which will look like:
scsi0: zfs-iscsi1:vm-105-disk-0
Start the VMs
Once the configuration is correct, start the VMs on either lab1 or lab2.
On lab1, start vm-111:
qm start 111On lab2:
qm start 112Verify VM Status
Check the status of the VMs to ensure they are running:
qm status 111
status: running
qm status 112
status: runningOptional: Migrate VMs for Balance
If needed those VMs can now be migrated live. To migrate vm-111 to lab2:
qm migrate 111 lab2 --onlineRemember there may not be a valid zpool snapshot for vm-111 on lab2, so it may take some time. I’ll expand on this failure recovery procedure in a future article.
When I needed to expand the space available in zfs-iscsi1 on lab2, the process was pretty straight forward. Follow the same instructions in my first article to create a new iSCSI target and 250GB LUN for each host in the cluster. For instance, I created lab1_lun4, lab2_lun4, and lab3_lun4. Use the iscsiadm commands for discovery against the QNAP NAS network interface that each lab cluster node is using. Follow same iscsiadm, lsblk and sgdisk commands to locate and label the new disk and enable auto login.
Extend the existing zfs-iscsi1 zpool with zpool add command. Use the newly added disk name as shown by lsblk, in this example /dev/sdh is the newly added disk:
zpool add zfs-iscsi1 /dev/sdh
zpool list
NAME SIZE ALLOC FREE ... FRAG CAP DEDUP HEALTH
rpool 928G 4.44G 924G 0% 0% 1.00x ONLINE
zfs-ssd1 476G 109G 367G 1% 22% 1.00x ONLINE
zfs-iscsi1 1.21T 183G 1.03T 5% 14% 1.00x ONLINEExpanded Architecture Enabling More Replication
To ensure dedicated high speed access to iSCSI disk LUNs and also to enable replication to multiple hosts, I revised the architecture to include an additional private 2.5Gb network segment dedicated to migration traffic. Using a dedicated 2.5Gb switch
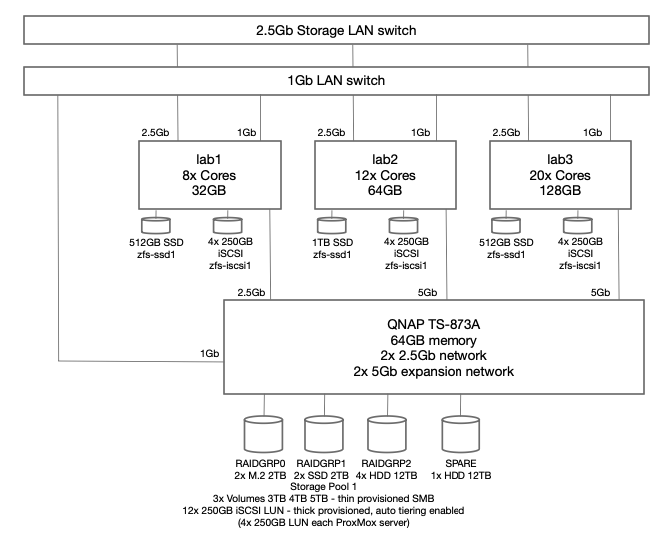
Specific migration configuration settings only apply to the entire cluster including all nodes. Unless otherwise configured, ProxMox will use the primary cluster IP addresses and NICs for migration traffic. Problem is that is typically the production network adapter and could only be 1 Gbs. Since I was using a dedicated NIC for iSCSI access, I decided to use dual NIC cards and use a dedicated 2.5Gb network segment for migration traffic, while the other NIC is dedicated to iSCSI traffic via a unique IPv4 subnet for each server connection to the QNAP server.
ProxMox documentation Migrate Configuration for Cluster
Migration configuration is located in /etc/pve/datacenter.cfg and has this syntax:
migration: [type=]<secure|insecure> [,network=<CIDR>]Migration traffic is encrypted using an SSH tunnel by default. On secure, completely private networks this can be disabled to increase performance.
migration: type=insecure,network=10.3.11.0/24Once the datacenter.cfg file has been updated, shortly (usually less than 30 seconds) ProxMox will start using the new network for migration traffic. Watching the migration progress dialog box we can see that transfer rates are routinely hitting 200MB/s and some peaks at 300MB/s. Bonus all that traffic does not compete with either Production network or iSCSI network traffic.
Next I’ll explore the HA Clustering capabilities of ProxMox.
After struggling to recover a moderately important VM on one of my home lab servers running generic CentOS libvirt, a colleague suggested I investigate ProxMox as a replacement to libvirt since it offers some replication and clustering features. The test was quick and I was very impressed with the features available in the community edition. It took maybe 15-30 minutes to install and get my first VM running. I quickly rolled ProxMox out on my other two lab servers and started experimenting with replication and migration of VMs between the ProxMox cluster nodes.
The recurring pain I was experiencing with VM hosts centered around primarily failed disks, both HDD and SSD, but also a rare processor failure. I had already decided to invest a significant amount of money into a commercial NAS (one of the major failures was irrecoverability of a TrueNAS VM with some archive files). Although investing in a QNAP or Synology NAS device would introduce a single point of failure for all the ProxMox hosts, I decided to start with one and see if later I could justify the cost for a redundant QNAP. More on that in another article.
The current architecture of my lab environment now looks like this:
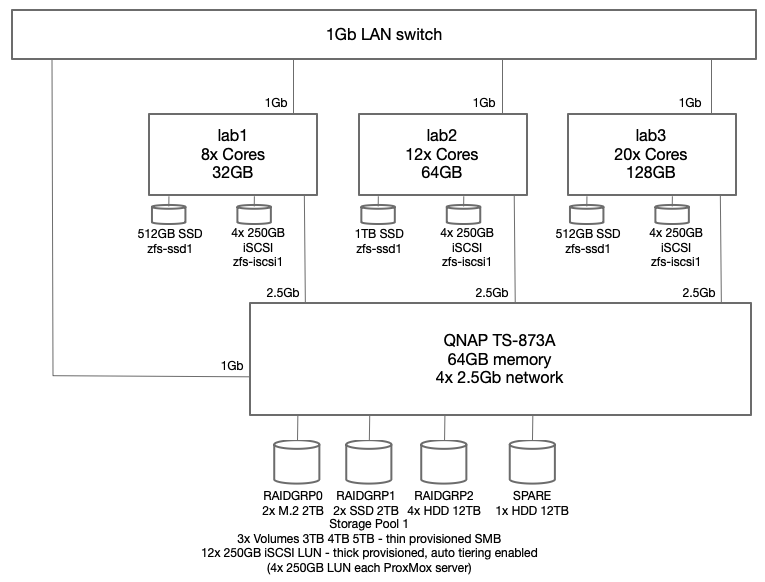
To reduce the complexity, I chose to setup ProxMox for replication of VM guests and allow live migration but not to implement HA clustering yet. To support this configuration, the QNAP NAS device is configured to advertise a number of iSCSI LUNs, each with a dedicated iSCSI target hosted on the QNAP NAS system. Through trial and error testing I decided to configure four (4) 250GB LUNs for each ProxMox host. All four (4) of those LUNs are added into a new ZFS zpool making 1TB of storage available to each ProxMox host. Since this iteration of the design is not going to use shared cluster aware storage, each host has a dedicated 1TB ZFS pool (zfs-iscsi1) however each pool is named the same to facilitate replication from one ProxMox host to another. For higher performance requirements, I also employ a single SSD on each host which have also been placed into a ZFS pool (zfs-ssd1) named the same on each host.
A couple of notes on architecture vulnerabilities. Each ProxMox host should have dual local disks to allow ZRAID1 mirroring. I chose to have only single SSD in each host to start with and tolerate a local disk failure – replication will be running on critical VM to limit the loss in the case of a local SSD failure. Any VM that cannot tolerate any disk failure will only use the iSCSI disks.
Boot into the ProxMox installer
Assuming the new host has dual disks that can be mirrored, chose Advanced for the boot disk and select ZRAID1 – this will allow you to select the two disks to be mirrored
Follow the installation prompts and sign in on the console after the system reboots
Use lsblk to identify local disks attached to find the SSD
lsblk
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 1G 0 part
└─sda3 8:3 0 930.5G 0 part
sdb 8:16 0 476.9G 0 disk
sdc 8:32 0 931.5G 0 disk
├─sdc1 8:33 0 1007K 0 part
├─sdc2 8:34 0 1G 0 part
└─sdc3 8:35 0 930.5G 0 part Clear the disk label if any and create empty GPT
sgdisk --zap-all /dev/sdb
sgdisk --clear --mbrtogpt /dev/sdbCreate ZFS pool with the SSD
zpool create zfs-ssd1 /dev/sdb
zpool list
NAME SIZE ALLOC FREE ... FRAG CAP DEDUP HEALTH
rpool 928G 4.44G 924G 0% 0% 1.00x ONLINE
zfs-ssd1 476G 109G 367G 1% 22% 1.00x ONLINEUpdate /etc/pve/storage.cfg and ensure ProxMox host is listed as a node for zfs-ssd1 pool. Initial entry can only list the first node. When adding another ProxMox host, the new host gets added to the nodes list.
zfspool: zfs-ssd1
pool zfs-ssd1
content images,rootdir
mountpoint /zfs-ssd1
nodes lab2,lab1,lab3Note the /etc/pve files are maintained in a global filesystem and any edits while on one host will reflect on all other ProxMox cluster nodes.
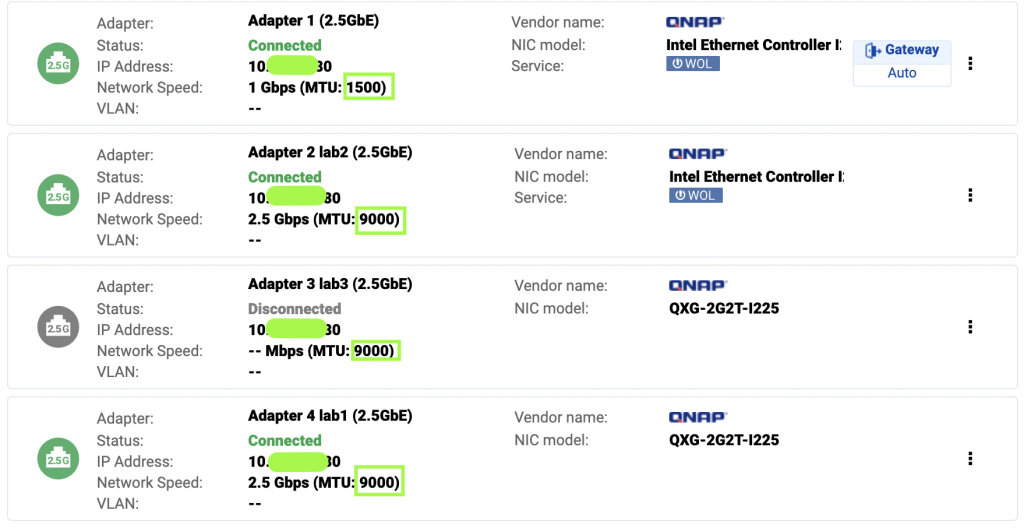
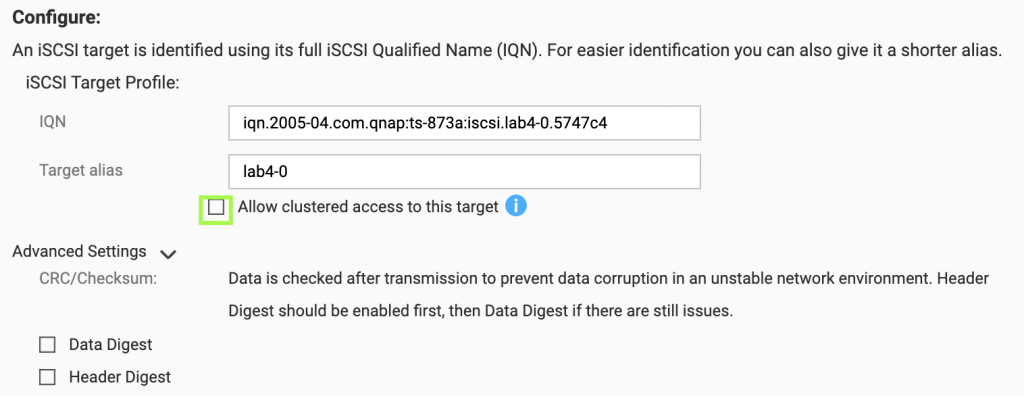
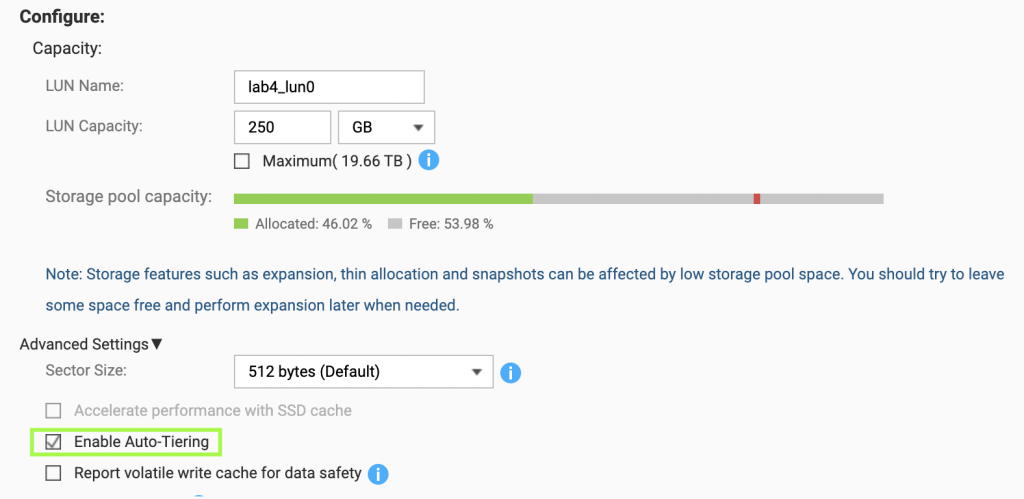
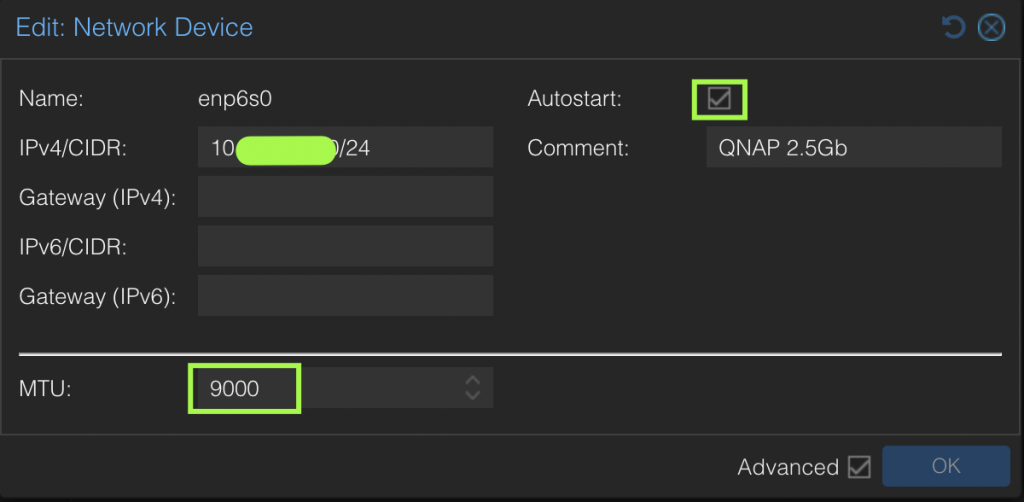
Update /etc/iscsi/iscsid.conf to setup automatic start, CHAP credentials
cp /etc/iscsi/iscsid.conf /etc/iscsi/iscsid.conf.orig
node.startup = automatic
node.session.auth.authmethod = CHAP
node.session.auth.username = qnapuser
node.session.auth.password = hUXxhsYUvLQAR
chmod o-rwx /etc/iscsi/iscsid.conf
systemctl restart iscsid
systemctl restart open-iscsiValidate connection to QNAP, ensure no sessions exist do discovery of published iSCSI targets. Ensure to use the high speed interface address of the QNAP.
iscsiadm -m session -P 3
No active sessions
iscsiadm -m discovery -t sendtargets -p 10.3.1.80:3260
10.3.1.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-0.5748c4
10.3.5.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-0.5748c4
10.3.1.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-1.5748c4
10.3.5.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-1.5748c4
10.3.1.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-2.5748c4
10.3.5.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-2.5748c4
10.3.1.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-3.5748c4
10.3.5.80:3260,1 iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-3.5748c4In the output of the discovery it appears there are two sets of targets. This is due to multiple network adapters under Network Portal on the QNAP being included in the targets. We will use the high speed address (10.3.1.80) for all the iscsiadm commands.
Execute login to each iSCSI target
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-0.5748c4 -p 10.3.1.80:3260 -l
Logging in to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-0.5748c4, portal: 10.3.1.80,3260]
Login to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-0.5748c4, portal: 10.3.1.80,3260] successful.
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-1.5748c4 -p 10.3.1.80:3260 -l
Logging in to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-1.5748c4, portal: 10.3.1.80,3260]
Login to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-1.5748c4, portal: 10.3.1.80,3260] successful.
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-2.5748c4 -p 10.3.1.80:3260 -l
Logging in to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-2.5748c4, portal: 10.3.1.80,3260]
Login to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-2.5748c4, portal: 10.3.1.80,3260] successful.
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-3.5748c4 -p 10.3.1.80:3260 -l
Logging in to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-3.5748c4, portal: 10.3.1.80,3260]
Login to [iface: default, target: iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-3.5748c4, portal: 10.3.1.80,3260] successful.Verify iSCSI disks were attached
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 1G 0 part
└─sda3 8:3 0 930.5G 0 part
sdb 8:16 0 476.9G 0 disk
├─sdb1 8:17 0 476.9G 0 part
└─sdb9 8:25 0 8M 0 part
sdc 8:32 0 931.5G 0 disk
├─sdc1 8:33 0 1007K 0 part
├─sdc2 8:34 0 1G 0 part
└─sdc3 8:35 0 930.5G 0 part
sdd 8:48 0 250G 0 disk
sde 8:64 0 250G 0 disk
sdf 8:80 0 250G 0 disk
sdg 8:96 0 250G 0 diskCreate GPT label on new disks
sgdisk --zap-all /dev/sdd
sgdisk --clear --mbrtogpt /dev/sdd
sgdisk --zap-all /dev/sde
sgdisk --clear --mbrtogpt /dev/sde
sgdisk --zap-all /dev/sdf
sgdisk --clear --mbrtogpt /dev/sdf
sgdisk --zap-all /dev/sdg
sgdisk --clear --mbrtogpt /dev/sdgCreate ZFS pool for iSCSI disks
zpool create zfs-iscsi1 /dev/sdd /dev/sde /dev/sdf /dev/sdg
zpool list
NAME SIZE ALLOC FREE ... FRAG CAP DEDUP HEALTH
rpool 928G 4.44G 924G 0% 0% 1.00x ONLINE
zfs-ssd1 476G 109G 367G 1% 22% 1.00x ONLINE
zfs-iscsi1 992G 113G 879G 0% 11% 1.00x ONLINESetup automatic login on boot for iSCSI disks
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-0.5748c4 -p 10.3.1.80 -o update -n node.startup -v automatic
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-1.5748c4 -p 10.3.1.80 -o update -n node.startup -v automatic
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-2.5748c4 -p 10.3.1.80 -o update -n node.startup -v automatic
iscsiadm -m node -T iqn.2005-04.com.qnap:ts-873a:iscsi.lab1-3.5748c4 -p 10.3.1.80 -o update -n node.startup -v automaticUpdate /etc/pve/storage.cfg for the zfs-iscsi1 ZFS pool to show up in the ProxMox GUI. Initial entry can only list the first node. When adding another ProxMox host, the new host gets added to the nodes list.
zfspool: zfs-iscsi1
pool zfs-iscsi1
content images,rootdir
mountpoint /zfs-iscsi1
nodes lab2,lab1,lab3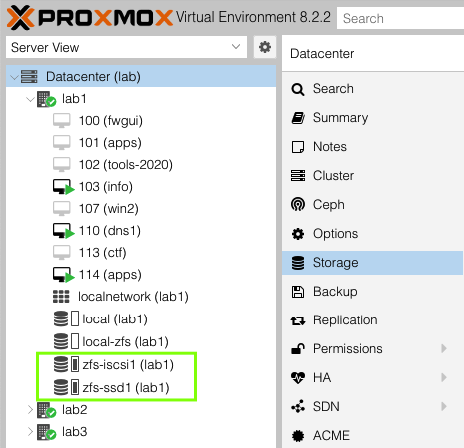
Next I will cover the configuration of VM for disk replication across one or more ProxMox hosts in this article How to Configure ProxMox VMs for Replication
Updated 2025/03/04
To complement the Raspberry Pi based Garden Controller I’ve designed and built, I decided to separate the irrigation valve and pump control onto a separate project and circuit board in order to make it more generically applicable. My intent is to make this Power Controller useful for any designer that has a computer capable of I2C communication.
Since this new Power Controller will be a generic controller that uses I2C communication, provides 24VAC for irrigation valves and also control of external power relays for two pumps, it needs to provide all it’s own power versus only relying on a 3.3v feed from the I2C host. I decided this will be the initial feature set:
3D PCB View

Design and Prototype
I used Kicad schematic and PCB design tools to begin building a dedicated power controller board. There is a trade off between having all of the switching and power functions on a single board versus moving the 120VAC switching off board to dedicated power relays. Given the possible high VAC current requirement for switching pumps, I found using the external relays allowed me to substantially reduce the PCB size and width of traces. At the same time, using a transformer that could supply 24VAC directly to the commercial irrigation valves would enable a compact design with minimal external components to the controller board. To offer maximum flexibility, I chose to add the ability to use a small number of the GPIO lines for either input or output along with a modest amount of external 3.3v, 5v and 12v power. The GPIO controller I chose was the MCP230017 which includes a built in I2C interface and two banks of 8 individually addressable I/O lines.
Due to the best valve relay choice and the fact that most of the external sensors I wanted to use, I chose to drive the MCP23017 at 5v although seems possible to also drive at 3.3v. For I2C and interrupt line to host interfaces I included 3.3v – 5v level converters since the Raspberry Pi I2C uses 3.3v levels.
For each of the relays we don’t need more than 40 mA so simple NPN 2N2222 transistors can be used to switch the relay coil voltage. Despite opting to use through-hole components versus surface mount so this board is easier to make for any hobbyists who use this design, I did want to reduce the component count and footprint where possible. Two areas include any pull-up or limiting resistors and all the kick-back diodes on all the switching transistors. DIP and SIP packages reduce both component count and board real estate.
Power Supply Design
Since the Power Controller needs to provide power for the irrigation valves and external pump control relays, I started with the valve requirements. Need to have 24VAC available to drive up to five (5) valves. I chose to use professional grade RainBird LVF075 Low Flow valves since I want reliable operation given the extensive irrigation I’m choosing to install. Given the in-rush and holding current required for each valve, the Hammond 183K24 transformer will suit given it’s 56VA maximum power factor.
Power Supply Specifications
Output (Internal)
5VDC 400mA max
.. each relay 40mA .. 200mA all on x 5 VDC = 1W
.. 200 mA max external supply = 2W
Output (External)
5x 24VAC 1.5 A – direct drive for 24VAC valves
2x 12VDC 70 mA – indirect drive for external 12VDC 120VAC relays
1x 3.3v AC sense interrupt line
3x 5v I/O lines programmable input or output
External 120VAC relays
Tnisesm 2PCS Power Relay DC12V Coil, 30A SPDT(1NO 1NC) 120 VAC with Flange Mounting and 10 Quick Connect Terminals Wires Mini Relay NT90-DC12V-10X
.. 70mA per coil .. 140mA x 12 VDC = 1.68W
Maximum power dissipation on LM340 without heatsink at 50C .. 2W
Other power dissipation guides: 10W enclosed, 20W vented with no heat sinks
Recommend no more than two (2) valves active simultaneously to limit dissipation in the enclosure that houses the PowerController. Pumps can be run simultaneously with valves due to low current draw.
Printed Circuit Board Design
Imported the schematic design to the KiCad PCB Editor and was quickly able to setup board dimensions, component layout and solder zones. Chose a two layer board to keep costs down, even though I chose to use a PCB manufacturer stateside. OSHPark is a great organization to work with that produces top quality boards. General design guidelines I followed include assigning hot or neutral to each of the two layers as well as north-south or east-west paths. Even following those guidelines I did need to use a small number of vias to route a path across a layer’s traces.
I heavily used the KiCad PCB Editor 3D view feature to help validate component placement on the circuit board. Most of the components were sources from Mouser Electronics, which has links to component symbols and footprints usable with most electronic design software (EDS) packages including KiCad. Where there wasn’t a component library available, typically you can request a part library be created. Samac will generate a zip file that contains symbol, footprint and even 3D model.
Assembly
Assembly of the board started with all the low profile components to make it easier to lay flat and hold the components in place while soldering.

Testing
Once all the low power components were installed I ran some simple bench tests by feeding 3.3v and 5v to the power via the I/O block intended to provide power output once the board is completed. Only the passive components were plugged into their respective sockets so voltage tests and relay tests could be done.

Both Valve 1 and Pump 1 were successfully activated via the manual test buttons. Since there wasn’t any high voltage or on-board power yet, I determined the Valve 1 test was successful by running a resistance check from V1+ terminal screw to a 24VAC FUSED pad and V1- terminal screw to a LV NEUT pad. All the other terminal screws were open/off to both their respective 24VAC and LV NEUT feeds.
Pump 1 activated by push button successfully provided 12VDC to the Pump 1 screw terminals.
Active Component Testing
I removed all power and installed the MCP23017 IC then connected the 3V3, SDA, SCL and GND terminal block pins to the test Raspberry Pi. I also ran 5VDC from the Raspberry to the 5VDC I/O terminal block since the power supply components are not soldered in yet.
Powered on the Raspberry Pi and saw the 3V3 and 5V LEDs light up. Ran an i2cdetect to test connection to the PowerController:
i2cdetect -y 1
0 1 2 3 4 5 6 7 8 9 a b c d e f
00: -- -- -- -- -- -- -- -- -- -- -- -- --
10: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
20: -- -- -- -- -- -- -- 27 -- -- -- -- -- -- -- --
30: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
40: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
50: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
60: -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- --
70: -- -- -- -- -- -- -- 77We can see the PowerController MCP23017 showing up at I2C address 0x27. We can also see a temperature and humidity sensor card at I2C address 0x77 on the same bus.
Power Controller Software
I chose to use the MCP23017 integrated GPIO controller due to the inclusive and compact hardware (simple single 20 pin DIP) and the extensive Python libraries available to simplify coding for status and control.
At github.com/allenpomeroy/PowerController I have developed a Python based control script powercontroller2.py
powercontroller2.py
–i2caddress: I2C address of the PowerController board, default 0x24
–testcount: Number of test cycles to run, default 3
–testontime: On time for tests (sec), default 1
–syslog: Send syslog status messages
–testofftime: Off time for tests (sec), default 1
–verbose: Print progress messages
–relay: [‘valve1’, ‘valve2’, ‘valve3’, ‘valve4’, ‘valve5’, ‘pump1’, ‘pump2’, ‘test’, ‘all’]
Name of relay to operate on
–action: [‘on’, ‘off’]
Action to perform on relay. Note relay ‘all’ can only accept action ‘off’
Update 2025/03/04
powercontroller2.py has been archived and you will now see two new scripts in the github.com/allenpomeroy/PowerController repository as I chose to split the controller code into a daemon that initializes the MCP and pin direction only once on startup. The client script (irrigation-controller.py) now only sends commands and listens for results on a socket, which avoids output relays unnecessarily being reset while simply looking for a state status.
While there is no limitation in the control script to prohibit multiple relays engaged at the same time, it is recommend to have no more than two (2) valves active simultaneously to limit heat dissipation in the enclosure that houses the PowerController. Both pumps can be run simultaneously with valves due to low current draw of the control relays.
Next software enhancement will be a webhook listener for the Raspberry Pi so applications have a clean interface to control the valves/pumps and get status. Think web based scheduling system or even iPhone / Android mobile app.

For any of the schematics, PCB manufacture or part lists feel free to email me powercontroller at pomeroy dot us.
Why does Red Hat Enterprise Linux 6 invalidate / discard packets when the route for outbound traffic differs from the route of incoming traffic?
Issue Description
Why does Red Hat Enterprise Linux 6 invalidate / discard packets when the route for outbound traffic differs from the route of incoming traffic?
Why does Red Hat Enterprise Linux 6 differ from Red Hat Enterprise Linux 5 in handling asymmetrically routed packets?
Solution posted at access.redhat.com/site/solutions/53031
Red Hat Enterprise Linux (RHEL) 6 Resolution
Temporary change
To accept asymmetrically routed (outgoing routes and incoming routes are different) packets set “rp_filter” to 2 and restart networking, by running the following commands:
echo 2 > /proc/sys/net/ipv4/conf/default/rp_filter
echo 2 > /proc/sys/net/ipv4/conf/all/rp_filter
Persistent change
To make this behaviour persistent across reboots, modify /etc/sysctl.conf and make the following change prior to reboot:
net.ipv4.conf.default.rp_filter = 2
Root Cause
RHEL6 (unlike RHEL5) defaults to using ‘Strict’ Reverse Path Forwarding (RPF) filtering.
Comments
The sysctl net.ipv4.conf.default.rp_filter selects the default RPF filtering setting for IPv4 networking. (It can be overridden per network interface through net.ipv4.interfacename.rp_filter).
Both RHEL6 and RHEL5 ship with a default /etc/sysctl.conf that sets this sysctl to 1, but the meaning of this value is different between the RHEL6 and the RHEL5 kernel.
Searching within Outlook 2010
Useful keyword searches:
category:=”Red Category”
read:no Items that have not been read. You can also use read:false to get the same results.
category:business Items that are categorized as business.
messagesize:enormous Items whose size is larger than 5 megabytes
Windows 7
Launch command window based on specific folder
Open command window here
Within Preview there is a filter that can be used to reduce the size of PDF files (think of PDF files that are 600 DPI high resolution). Unfortunately it produces very poor quality images to the point of being unusable. Fortunately there is a way to create and install your own custom quartz filters for use in Preview that give large file size reductions while maintaining good quality.
After some googling, I found a perfect article that explains why the default Mac OS X Reduce File Size filter produces terrible quality images .. and how to fix that:
http://hints.macworld.com/article.php?story=20120629091437274
The filter, which is just a XML file, can be edited with any text or programming editor then saved to the /System/Library/Filters directory with a unique filename. The Reduce File Size (Good) filter is what I use .. rather than posting as a code block and messing around with escaping the XML so the code displays correctly, the file is available for [download here].
Simply download the contents of this file, ensure it is renamed to a .qfilter file, then copy into the system filter directory (so it is available for all users). I chose to use /System/Library/Filters/Reduce File Size Good.qfilter. You may need to be a Mac OS X Administrator to write this file into the shared system library folder. At this point, in Preview you can use this filter to reduce large scanned PDF files by almost a magnitude of order.
Here is the text of the original post:
Make your own Reduce File Size presets for PDF export
Jul 05, ’12 07:30:00AM Contributed by: zpjet
I was never satisfied with results of “Reduce File Size” Quartz filter when trying to make some PDFs smaller before sending them by e-mail. It made them too small, and the graphics were fuzzy.
I eventually found where these filters are:
/System/Library/Filters
I was delighted to find out they’re XML files easily editable with TextEdit (or any other text editor). I also found why this particular filter makes quite unusable PDFs, as these parameters were just too low:
Compression Quality 0.0
ImageSizeMax 512
So I copied this file to my Desktop, and then made two more copies of it, and called them Reduce File Size Good, Better and Best. Then I changed the parameters of each file to 0.25, 0.5 and 0.75 for Compression Quality, and used these three values for ImageSizeMax:
842 (that’s A4 at 72dpi)
1684 (A4 at 144dpi)
3508 (A4 at 300dpi)
Finally, I changed the default string for the Name key at the end of each file to reflect the three settings, so they display the names I have given them in the menu.
Then I copied them to a /Library/Filters folder I created (for some reason, ~/Library/Filters doesn’t work in Lion) and now when I open a picture or PDF in Preview, I have the option of four different qualities for reduced file sizes.
As an example, I have a JPEG of scanned A4 invoice at 300dpi and it’s 1.6MB. When exporting to PDF in reduced size, the file is only 27 KB and it’s quite unusable – very fuzzy and hard to read. The Good one is much easier to read, slightly fuzzy and still only 80 KB. Better is 420 KB and clear, and the Best is 600 KB and almost as good as the original even on a laser printer.
Apple has been continuously dumbing down the AirPort Utility to the point where their default AirPort Utility (version 6.x) is virtually useless. Settings such as syslog destination, NTP settings, etc can only be set with AirPort Utility 5.6 – problem is it cannot be loaded on Mountain Lion (10.8.4). Discussion here at https://discussions.apple.com/thread/4172563?start=15&tstart=0 shows how to install AirPort Utility 5.6.1 on ML without clobbering version 6.
In case Apple removes that thread (written by Douglas Urner), here it is:
Just in case you’d like to use AirPort Utility 5.6.1 on Mountain Lion (and probably Lion as well), here’s how to install it:
That pretty much does it. I hope it helps somebody out there.
I’ve been using Pixelmator to create my iPhone wallpaper .. ![]() .. and storing at this path:
.. and storing at this path: 
![]()
So I’ve had to replace a Seagate disk yet again and spent a frustrating amount of time on their website looking for a link to their warrenty replacement page >> http://www.seagate.com/support/warranty-and-replacements/
At least this time, I’m using Linux software RAID for a RAID1 mirroring configuration. When I determined there was a disk failure, I used the following mdadm commands to remove the bad drive:
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sda1[0](F) sdb1[2]
5139084 blocks [2/1] [U_]
md1 : active raid1 sda2[0](F) sdb2[2]
9841585344 blocks [2/1] [U_]
unused devices:
– Fail and remove all /dev/sdb partitions (/dev/sdb1, /dev/sdb2)
# mdadm --manage /dev/md0 --fail /dev/sdb1
mdadm: set /dev/sdb1 faulty in /dev/md0
# mdadm --manage /dev/md0 --remove /dev/sdb1
mdadm: hot removed /dev/sdb1
# mdadm --manage /dev/md1 --fail /dev/sdb3
mdadm: set /dev/sdb3 faulty in /dev/md1
# mdadm --manage /dev/md1 --remove /dev/sdb3
mdadm: hot removed /dev/sdb3
– Shutdown and replace the bad disk (assuming you have been able to replace with the exact disk)
– Copy the partition table from the surviving disk
# sfdisk -d /dev/sda | sfdisk /dev/sdb
– Re-attach the partitions from /dev/sdb to the RAID1 mirrors:
# mdadm --manage /dev/md0 --add /dev/sdb1
# mdadm --manage /dev/md1 --add /dev/sdb2
You should now see the md devices syncing up by:
# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sda1[1] sdb1[2]
5139084 blocks [2/1] [U_]
[======>.......] recovery = 49.3% ...
Once the sync completes, install grub on both the drives again:
# grub
grub> root (hd0,0)
grub> setup (hd0)
grub> root (hd1,0)
grub> setup (hd1)
Great reference pages:
http://serverfault.com/questions/483141/mdadm-raid-1-grub-only-on-sda
https://blogs.it.ox.ac.uk/jamest/2011/07/26/software-raid1-plus-grub-drive-replacement/